The realms of technology are ever-evolving, necessitating periodic assessments and revisions to ensure our projects stay optimized and efficient. Such was the fate of my audio-centric project. With a clear vision in mind and challenges identified, I embarked on a journey to re-engineer the architecture, a journey that led me to eliminate TCPServer communication and embrace the power of Raspberry Pi. This article offers an in-depth look into this transformative journey, highlighting the changes, improvements, and the rationale behind each decision.
The Choice of Clean Architecture
Before diving into the architecture’s specifics, it’s crucial to address an underlying principle that guided my decisions – the adoption of Clean Architecture. This architecture emphasizes a separation of concerns, ensuring that software remains independent of frameworks, UI, and external agencies. It primarily:
– Promotes Flexibility: The decoupling of software components means one can easily switch out parts without affecting the system’s core.
– Ensures Scalability: As the project grows, so can the architecture, seamlessly accommodating new features.
– Facilitates Testing: Components can be tested in isolation, ensuring rigorous quality checks.
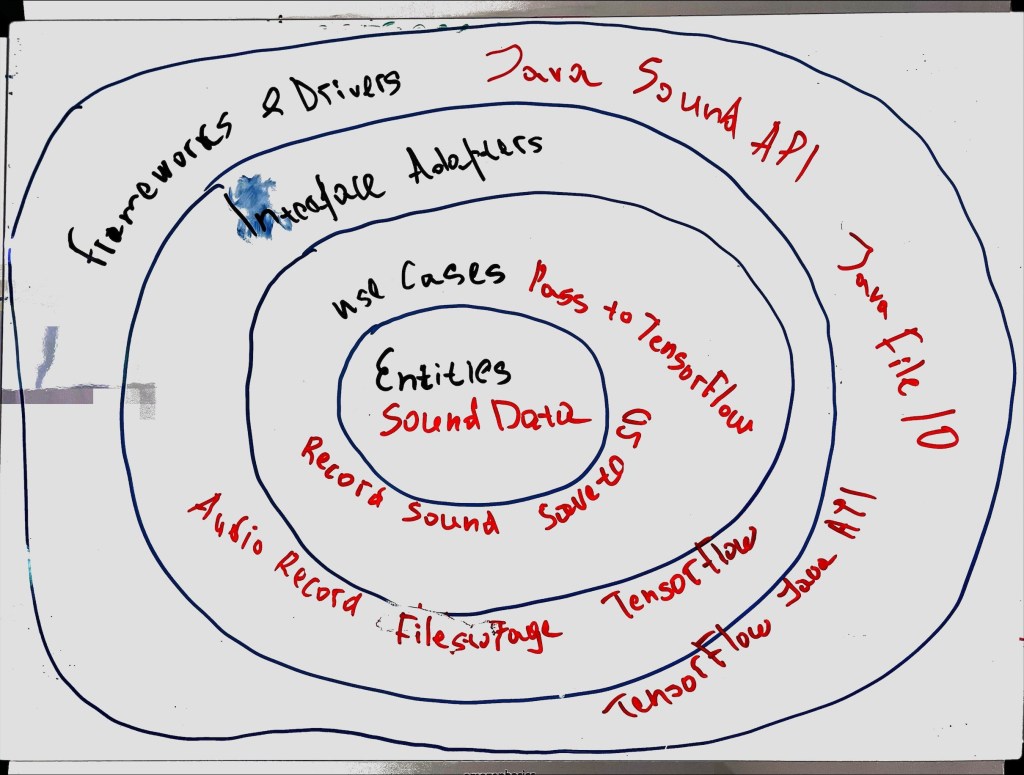
Such benefits made Clean Architecture an evident choice, providing a robust foundation upon which the project’s functionalities could be built, tested, and scaled.
Entities & Use Cases:
Central to the project is the business logic module. Here, guidelines and requirements meticulously dictate audio recording processes, data storage mechanisms, and TensorFlow model integrations.
Interface Adapters:
– Audio Recorder Adapter: Through interfaces like Java Sound API, this adapter oversees audio recording, connecting seamlessly to the microphone.
– File Storage Adapter:Tasked with safeguarding audio recordings, it operates on the SD card or alternative storage mediums.
– TensorFlow Model Adapter: Serving as a conduit, it channels audio data to the TensorFlow model for precise processing.
Frameworks & Drivers:
– Java’s Sound API: The primary tool for capturing audio.
– Java’s File API: Manages audio storage functionalities.
– TensorFlow’s Java API: Anchoring machine learning processes in the system, it ensures thorough audio data analytics.
The Decision to Remove Teensy 4.1
The journey towards optimization involved making some tough choices. One such decisive move was to distance from the combination of „Teensy 4.1 and microphone KY-038.“ The motivation? A glaring issue of inadequate audio quality. The audio recordings emanating from this setup were not just deficient in clarity but were also unsuitable for any meaningful analysis. In the domain of audio processing, where quality is paramount, this shortcoming was untenable.
Raspberry Pi came to the rescue. A potent device, it guarantees pristine audio recordings, ensuring that the captured data is ripe for accurate analysis. This shift not only addressed the quality concerns but also harmonized seamlessly with the principles of Clean Architecture, resulting in a streamlined, efficient project structure.
Comparative Analysis of the Two Architectures
1. Architecture with TCPServer and Teensy 4.1 + Microphone KY-038:
Primary Components:
Teensy 4.1 microcontroller and KY-038 microphone for audio capture.
TCPServer: Accepts and stores audio data transmitted from the Teensy.
Workflow:
Audio capture via the KY-038 microphone and Teensy 4.1.
Audio data transmission from Teensy 4.1 to the TCPServer.
Audio data storage for subsequent processing.
Challenges & Limitations:
Sub-par audio quality from the Teensy 4.1 and KY-038 combination.
Additional complexities due to TCPServer’s integration.
2. Revised Architecture with Raspberry Pi (sans Teensy 4.1):
Primary Components:
Raspberry Pi for efficient audio capture and processing.
Direct TensorFlow model integration, obviating the need for external servers.
Workflow:
Direct audio capture via the Raspberry Pi.
Audio data either stored on an SD card or immediately processed through the TensorFlow model on the Raspberry Pi.
Advantages:
Enhanced audio capture and processing using the Raspberry Pi.
Simplified workflow due to the absence of the TCPServer, leading to faster processing times and minimized data transfer issues.
In juxtaposing these two architectures, the Raspberry Pi-centric structure emerges superior. It promises streamlined operations, efficiency, and high-quality audio capture and processing.
In conclusion, adapting and innovating are integral to technological endeavors. This project’s metamorphosis, underlined by the principles of Clean Architecture and motivated by the need for quality, exemplifies this ethos. The transition to Raspberry Pi-centric architecture signifies a monumental leap forward, setting the stage for an efficient, high-quality audio processing future.
